Robots.txt Tutorial
![]()
How to Create Robots.txt Files
Use our Robots.txt generator to create a robots.txt file.
Analyze Your Robots.txt File
Use our Robots.txt analyzer to analyze your robots.txt file today.
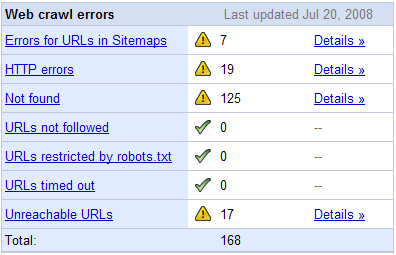
Google also offers a similar tool inside of Google Webmaster Central, and shows Google crawling errors for your site.
Example Robots.txt Format
Allow indexing of everything
User-agent: *
Disallow:
or
User-agent: *
Allow: /
Disallow indexing of everything
User-agent: *
Disallow: /
Disawllow indexing of a specific folder
User-agent: *
Disallow: /folder/
Disallow Googlebot from indexing of a folder, except for allowing the indexing of one file in that folder
User-agent: Googlebot
Disallow: /folder1/
Allow: /folder1/myfile.html
Background Information on Robots.txt Files
- Robots.txt files inform search engine spiders how to interact with indexing your content.
- By default search engines are greedy. They want to index as much high quality information as they can, & will assume that they can crawl everything unless you tell them otherwise.
- If you specify data for all bots (*) and data for a specific bot (like GoogleBot) then the specific bot commands will be followed while that engine ignores the global/default bot commands.
- If you make a global command that you want to apply to a specific bot and you have other specific rules for that bot then you need to put those global commands in the section for that bot as well, as highlighted in this article by Ann Smarty.

- If you make a global command that you want to apply to a specific bot and you have other specific rules for that bot then you need to put those global commands in the section for that bot as well, as highlighted in this article by Ann Smarty.
- When you block URLs from being indexed in Google via robots.txt, they may still show those pages as URL only listings in their search results. A better solution for completely blocking the index of a particular page is to use a robots noindex meta tag on a per page bases. You can tell them to not index a page, or to not index a page and to not follow outbound links by inserting either of the following code bits in the HTML head of your document that you do not want indexed.
- <meta name="robots" content="noindex"> <-- the page is not indexed, but links may be followed
- <meta name="robots" content="noindex,nofollow"> <-- the page is not indexed & the links are not followed
- Please note that if you do both: block the search engines in robots.txt and via the meta tags, then the robots.txt command is the primary driver, as they may not crawl the page to see the meta tags, so the URL may still appear in the search results listed URL-only.
- If you do not have a robots.txt file, your server logs will return 404 errors whenever a bot tries to access your robots.txt file. You can upload a blank text file named robots.txt in the root of your site (ie: seobook.com/robots.txt) if you want to stop getting 404 errors, but do not want to offer any specific commands for bots.
- Some search engines allow you to specify the address of an XML Sitemap in your robots.txt file, but if your site is small & well structured with a clean link structure you should not need to create an XML sitemap. For larger sites with multiple divisions, sites that generate massive amounts of content each day, and/or sites with rapidly rotating stock, XML sitemaps can be a helpful tool for helping to get important content indexed & monitoring relative performance of indexing depth by pagetype.
Crawl Delay
- Search engines allow you to set crawl priorities.
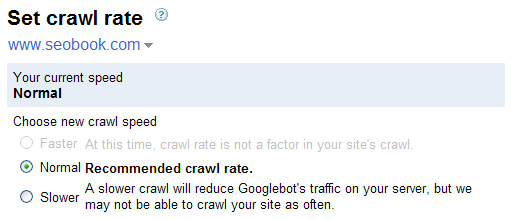
- Google does not support the crawl delay command directly, but you can lower your crawl priority inside Google Webmaster Central.
- Google has the highest volume of search market share in most markets, and has one of the most efficient crawling priorities, so you should not need to change your Google crawl priority.
- Google has the highest volume of search market share in most markets, and has one of the most efficient crawling priorities, so you should not need to change your Google crawl priority.
You can set Yahoo! Slurp crawl delays in your robots.txt file.(Note: in most major markets outside of Japan Yahoo! Search is powered by Bing, while Google powers search in Yahoo! Japan).Their robots.txt crawl delay code looks like
User-agent: Slurp
Crawl-delay: 5
where the 5 is in seconds.
- Microsoft's information for Bing is located here.
- Their robots.txt crawl delay code looks like
User-agent: bingbot
Crawl-delay: 10
where the 10 is in seconds.
- Their robots.txt crawl delay code looks like
- Google does not support the crawl delay command directly, but you can lower your crawl priority inside Google Webmaster Central.
Robots.txt Wildcard Matching
Google and Microsoft's Bing allow the use of wildcards in robots.txt files.
To block access to all URLs that include a question mark (?), you could use the following entry:
User-agent: *
Disallow: /*?
You can use the $ character to specify matching the end of the URL. For instance, to block an URLs that end with .asp, you could use the following entry:
User-agent: Googlebot
Disallow: /*.asp$
More background on wildcards available from Google and Yahoo! Search.
URL Specific Tips
Part of creating a clean and effective robots.txt file is ensuring that your site structure and filenames are created based on sound strategy. What are some of my favorite tips?
- Avoid Dates in URLs: If at some point in time you want to filter out date based archives then you do not want dates in your file paths of your regular content pages or it is easy to filter out your regular URLs. There are numerous other reasons to avoid dates in URLs as well.
- End URLs With a Backslash: If you want to block a short filename and it does not have a backslash at the end if it then you could accidentally end up blocking other important pages.
- Consider related URLs if you use Robots.txt wildcards: I accidentally cost myself over $10,000 in profit with one robots.txt error!
- Dynamic URL Rewriting: Yahoo! Search offers dynamic URL rewriting, but since most other search engines do not use it, you are probably better off rewriting your URLs in your .htaccess file rather than creating additional rewrites just for Yahoo! Search. Google offers parameter handling options & rel=canonical, but it is generally best to fix your public facing URLs in a way that keeps them as consistent as possible, such that
- if you ever migrate between platforms you do not have many stray links pointing into pages that no longer exist
- you do not end up developing a complex maze of gotchas as you change platforms over the years
- Sites across markets & languages: Search engines generally try to give known local results a ranking boost, though in some cases it can be hard to build links into many local versions of a site. Google offers hreflang to help them know which URLs are equivalents across languages & markets.
- More URL tips in the naming files section of our SEO training program.
Sample Robot Oddities
Google Generating Search Pages on Your Site?
Google has begun entering search phrases into search forms, which may waste PageRank & has caused some duplicate content issues. If you do not have a lot of domain authority you may want to consider blocking Google from indexing your search page URL. If you are unsure of the URL of your search page, you can conduct a search on your site and see what URL appears. For instance,
- The default Wordpress search URL is usually ?s=
- Adding
User-agent: *
Disallow: /?s=
to your robots.txt file would prevent Google from generating such pages
- Adding
- Drupal powers the SEO Book site, and our default Drupal search URL is /search/node/
Noindex instead of Disallow in Robots.txt?
Typically a noindex directive would be included in a meta robots tag. However, Google for many years have supported using noindex inside Robots.txt, similarly to how a webmaster would use disallow.
User-agent: Googlebot
Disallow: /page-uno/
Noindex: /page-uno/
The catch, as noticed by Sugarrae, is URLs which are already indexed but are then set to noindex in robots.txt will throw errors in Google's Search Console (formerly known as Google Webmaster Tools). Google's John Meuller also recommended against using noindex in robots.txt.
Secured Version of Your Site Getting Indexed?
In this guest post by Tony Spencer about 301 redirects and .htaccess he offers tips on how to prevent your SSL https version of your site from getting indexed. In the years since this was originally published, Google has indicated a preference for ranking the HTTPS version of a site over the HTTP version of a site. There are ways to shoot yourself in the foot if it is not redirected or canonicalized properly.
Have Canonicalization or Hijacking Issues?
Throughout the years some people have tried to hijack other sites using nefarious techniques with web proxies. Google, Yahoo! Search, Microsoft Live Search, and Ask all allow site owners to authenticate their bots.
- While I believe Google has fixed proxy hijacking right now, a good tip to minimize any hijacking risks is to use absolute links (like <a href="http://www.seobook.com/about.shtml">) rather than relative links (<a href="about.shtml">) .
- If both the WWW and non WWW versions of your site are getting indexed you should 301 redirect the less authoritative version to the more important version.
- The version that should be redirected is the one that does not rank as well for most search queries and has fewer inbound links.
- Back up your old .htaccess file before changing it!
Want to Allow Indexing of Certain Files in Folder that are Blocked Using Pattern Matching?
Aren't we a tricky one!
Originally robots.txt only supported a disallow directive, but some search engines also support an allow directive. The allow directive is poorly documented and may be handled differently by different search engines. Semetrical shared information about how Google handles the allow directive. Their research showed:
The number of characters you use in the directive path is critical in the evaluation of an Allow against a Disallow. The rule to rule them all is as follows:
A matching Allow directive beats a matching Disallow only if it contains more or equal number of characters in the path
Comparing Robots.txt to...
link rel=nofollow & Meta Robots Noindex/Nofollow Tags
 |
Crawled by Googlebot? |
Appears in Index? |
Consumes PageRank |
Risks? Waste? |
Format |
| robots.txt | no | If document is linked to, it may appear URL only, or with data from links or trusted third party data sources like the ODP | yes | People can look at your robots.txt file to see what content you do not want indexed. Many new launches are discovered by people watching for changes in a robots.txt file. Using wildcards incorrectly can be expensive! |
User-agent: * OR User-agent: * Complex wildcards can also be used. |
| robots meta noindex tag | yes | no | yes, but can pass on much of its PageRank by linking to other pages | Links on a noindex page are still crawled by search spiders even if the page does not appear in the search results (unless they are used in conjunction with nofollow). Page using robots meta nofollow (1 row below) in conjunction with noindex can accumulate PageRank, but do not pass it on to other pages. |
<meta name="robots" content="noindex"> OR can be used with nofollow likeso <meta name="robots" content="noindex,nofollow"> |
| robots meta nofollow tag | destination page only crawled if linked to from other documents | destination page only appears if linked to from other documents | no, PageRank not passed to destination | If you are pushing significant PageRank into a page and do not allow PageRank to flow out from that page you may waste significant link equity. | <meta name="robots" content="nofollow"> OR can be used with noindex likeso <meta name="robots" content="noindex,nofollow"> |
| link rel=nofollow | destination page only crawled if linked to from other documents | destination page only appears if linked to from other documents | Using this may waste some PageRank. It is recommended to use on user generated content areas. | If you are doing something borderline spammy and are using nofollow on internal links to sculpt PageRank then you look more like an SEO and are more likely to be penalized by a Google engineer for "search spam" | <a href="http://destination.com/" rel="nofollow">link text</a> |
| rel=canonical | yes. multiple versions of the page may be crawled and may appear in the index | pages still appear in the index. this is taken as a hint rather than a directive. | PageRank should accumulate on destination target | With tools like 301 redirects and rel=canonical there might be some small amount of PageRank bleed, particularly with rel=canonical since both versions of the page stay in the search index. | <link rel="canonical" href="http://www.site.com/great-page" /> |
| Javascript link | generally yes, as long as the destination URL is easily accessible in the a href or onclick portions of the link | destination page only appears if linked to from other documents | generally yes, PageRank typically passed to destination | While many of these are followed by Google, they may not be followed by other search engines. |
|
Data Sources
- this 2007 interview of Google's Matt Cutts by Eric Enge.
- the announcement of the rel=canonical element.
- Vanessa Fox reporting on Google's 2009 I/O conference.
- Matt Cutts 2009 post on rel="nofollow" consuming PageRank.
More Robots.txt Resources
- Controlling Crawling and Indexing - "This document represents the current usage of the robots.txt web-crawler control directives as well as indexing directives as they are used at Google. These directives are generally supported by all major web-crawlers and search engines."
- Robots Exclusion Protocol for Google & Microsoft's Bing
- jane and robot - Vanessa Fox offers tips on managing robot's access to your website.
- robotstxt.org - the old school official site about web robots and robots.txt
More Robots Control Goodness
- hreflang - use this tag to highlight equivalent pages in other languages and/or regions
- vary HTTP header - an option for optimizing site display on mobile phones
Gain a Competitive Advantage Today
Your top competitors have been investing into their marketing strategy for years.
Now you can know exactly where they rank, pick off their best keywords, and track new opportunities as they emerge.
Explore the ranking profile of your competitors in Google and Bing today using SEMrush.
Enter a competing URL below to quickly gain access to their organic & paid search performance history - for free.
See where they rank & beat them!
- Comprehensive competitive data: research performance across organic search, AdWords, Bing ads, video, display ads, and more.
- Compare Across Channels: use someone's AdWords strategy to drive your SEO growth, or use their SEO strategy to invest in paid search.
- Global footprint: Tracks Google results for 120+ million keywords in many languages across 28 markets
- Historical performance data: going all the way back to last decade, before Panda and Penguin existed, so you can look for historical penalties and other potential ranking issues.
- Risk-free: Free trial & low monthly price.



